

Throughout my career as a video game localizer, I’ve encountered varied Steam game titles. Some are so head-turning that the bon mot captivates me to explore more about the game, while others, well, are just names. One reason behind this is the overused words that wear out my curiosity. Trendy buzzwords can have their place, but their excessive use dulls their impact. To combat this, I propose analyzing the most overused words in Steam game titles today. By pinpointing these stale expressions in my language pair, Simplified Chinese and English, I can avoid resorting to clichéd title localization and ultimately enhance the game’s search engine optimization (SEO).
In this game-laden world, we are surrounded by a diverse range of game distributors, but none of them can rival the influence of Steam. That’s why I decided to leverage the power of Python and build a project that delves into the rich trove of game data that Steam offers.
Project goals:
- Acquire public game names on Steam, excluding DLCs, artbooks, soundtracks, demos, etc;
- Categorize the game names by language;
- Interrogate names in zh-CN and EN to count the top 20 words used;
- Output the final result in an Excel file. Create tabs by language.
Nik Davis wrote an inspiring article 5 years ago. Unlike the detailed instructions mentioned in the article, I don’t need data from SteamSpy because some information such as genres, owners, and prices are irrelevant to my needs. So I choose to directly request data from the Steam AppList, a reference from Steamworks API.
Codes and tweaks
# Import libraries
Importing the libraries I will be using is the first step.
import requests
import pandas as pd
from collections import Counter
import re
import os
import time
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
import jieba
import nltk
from nltk.corpus import stopwords
Since language category and counting overused words is one of my main goals, I also need to download nltk data.
nltk.download(‘stopwords’, quiet=True)
nltk.download(‘punkt’, quiet=True)
# Data acquisition
Using a request to collect data from AppList.
print(“Fetching data from Steam API…”)
url = “https://api.steampowered.com/ISteamApps/GetAppList/v2/”
response = requests.get(url)
data = response.json()
print(“Processing data…”)
apps = data[‘applist’][‘apps’] # Process all Steam games
total_apps = len(apps)
print(f”Total number of apps: {total_apps}”)
df = pd.DataFrame(apps)
Also of note is that developers may mix language terms in their titles. For example, names like “隐秘世界 – Underworld Online”, “꿈을 빼앗긴 남자 – Dream invader”, or “Бройлеры Demo” can be difficult to call which language is prior. To generate a clean data set, I manually set out the category logic. The priority level in languages is Japanese, Korean, Chinese, Russian, and English: as long as the name includes a linguistic unit in the higher-level language, then it’s labeled as such. Games of English titles are acceptable to gamers from Europe, North America, and vast regions, so it’s pointless to differentiate if it’s written in Spanish, Italian, or English. MENA regions are dominated by Arabic, yet the said URL link didn’t provide eligible names.
def detect_language(text):
# Detect language based on character sets
if re.search(r'[\u3040-\u30ff]’, text): # Japanese character range
return ‘Japanese’
elif re.search(r'[\uac00-\ud7a3]’, text): # Korean character range
return ‘Korean’
elif re.search(r'[\u4e00-\u9fff]’, text): # Chinese character range
return ‘Chinese’
elif re.search(r'[\u0400-\u04FF]’, t
ext):
# Russian character range
return ‘Russian’
else:
return ‘English’ # Default to English if no other language detected
# Clean noises
During my early tests, I found generic terms such as “set”, “demo”, “soundtrack”, etc, polluted the output. In Chinese, a similar issue occurred. “设定/set”, “拓展/expansion”, “试玩/demo”, etc were not content words I needed. So words like them have to be ruled out. The minimum length for a semantical Chinese word is usually 2 hanzi, yet 3-hanzi words exist as well, such as “大冒险/saga”, “幸存者/survivor”, etc. Here I count both 2-hanzi words and 3-hanzi words.
def is_chinese_char(char):
return ‘\u4e00’ <= char <= ‘\u9fff’
def get_top_chinese_words(text_series, n=20):
word_counts = Counter()
excluded_words = {‘设定’, ‘拓展’, ‘试玩’, ‘试玩版’, ‘原声’, ‘音乐包’, ‘资料片’, ‘捆绑包’}
for text in text_series:
# Remove English terms
english_terms = [‘soundtrack’, ‘
playtest’, ‘demo’, ‘dlc’, ‘pack’, ‘artbook’, ‘set’, ‘original’, ‘trailer’]
for term in english_terms:
text = text.lower().replace(term, ”)
# Segment Chinese text
words = jieba.lcut(text)
# Count 2-character and 3-character Chinese words
for word in words:
if len(word) in [2, 3] and all(is_chinese_char(char) for char in word) and word not in excluded_words:
word_counts[word] += 1
# Return top n words
return word_counts.most_common(n)
English is much easier to cut back on non-content words because the word length does not affect their semantical function. Punctuations also appeared in my early tests. So let’s remove them too.
def get_top_english_words(text_series, n=20):
stop_words = set(stopwords.words(‘english’))
additional_stop_words = {‘soundtrack’, ‘playtest’, ‘demo’, ‘dlc’, ‘pack’, ‘artbook’, ‘set’, ‘original’, ‘trailer’, ‘edition’, }
stop_words.update(additional_stop_words)
words = ‘ ‘.join(text_series).lower()
words = re.findall(r’\w+’, words) # Extract word
s, removing punctuation
content_words = [word for word in words if word not in stop_words and len(word) > 2]
# Return top n words, excluding those with punctuation
return [item for item in Counter(content_words).most_common(n) if not re.search(r'[^\w\s]’, item[0])]
Since there are more than 200,000 games on Steam, the data interrogation can take a long time to process. A simple progress bar can indicate how many game names have been processed and if the program is still running when I am waiting.
print(“Detecting languages…”)
start_time = time.time()
for i, row in df.iterrows():
if i % 1000 == 0: # Print progress every 1000 apps
print(f”Processed {i} apps out of {total_apps} ({i/total_apps*100:.2f}%)…”)
df.at[i, ‘language’] = detect_language(row[‘name’])
print(“Analyzing top words…”)
# Count buzzwords
Now the data have been analyzed. It’s time to print the results and create an Excel for them.
chinese_top_words = get_top_chinese_words(df[df[‘language’] == ‘Chinese’][‘name’])
english_top_words = get_top_english_words(df[df[‘language’] == ‘English’][‘name’])
print(“\nTop 20 Chinese words (2-3 characters):”)
for word, count in chinese_top_words:
print(f”{word}: {count}”)
print(“\nTop 20 content words in English:”)
for word, count in english_top_words:
print(f”{word}: {count}”)
print(“\nCreating Excel file…”)
desktop = os.path.join(os.path.expanduser(‘~’), ‘Desktop’)
excel_path = os.path.join(desktop, ‘steam_apps_analysis_full.xlsx’)
wb = Workbook()
wb.remove(wb.active) # Remove default sheet
First I need to create sheets for each language.
for lang in df[‘language’].unique():
ws = wb.create_sheet(title=lang[:31]) # E
xcel sheet names are limited to 31 characters
lang_df = df[df[‘language’] == lang]
for r in dataframe_to_rows(lang_df, index=False, header=True):
ws.append(r)
I can have a summary sheet for the general info.
summary_sheet = wb.create_sheet(title=’Summary’, index=0)
summary_sheet.append([‘Language’, ‘Nu
mber of Apps’])
for lang, count in df[‘language’].value_counts().items():
summary_sheet.append([lang, count])
summary_sheet.append([])
summary_sheet.append([‘Top 20 Chinese Words
(2-3 characters)’])
for word, count in chinese_top_words:
summary_sheet.append([word, count])
summary_sheet.append([])
summary_sheet.append([‘Top 20 English Conte
nt Words’])
for word, count in english_top_words:
summary_sheet.append([word, count])
The last step is to save the file.
wb.save(excel_path)
Results in English and Simplified Chinese
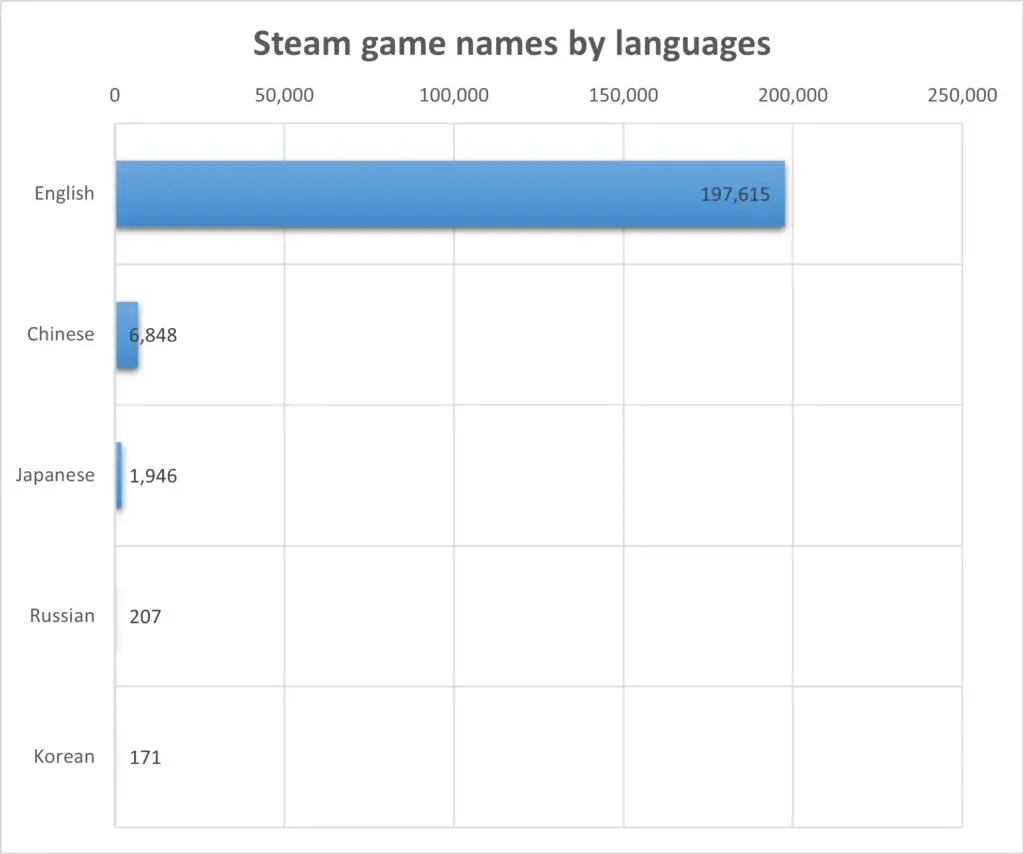
Now, the tedious coding part is behind us. It is the moment to unveil the fascinating puzzle. Steam is indeed a chest full of gems. By Jun 22, 2024, when I accessed the data and wrote this article, there were 206,774 games in the Steam marketplace. Keep in mind that this figure excludes artbooks, DLCs, soundtracks, and demos, providing a clearer picture of base games. English names still lead the first place, significantly outnumbering names in other languages multiple times. This dominance aligns with our real-world experience: English offers a common ground, fostering comprehension for gamers worldwide.
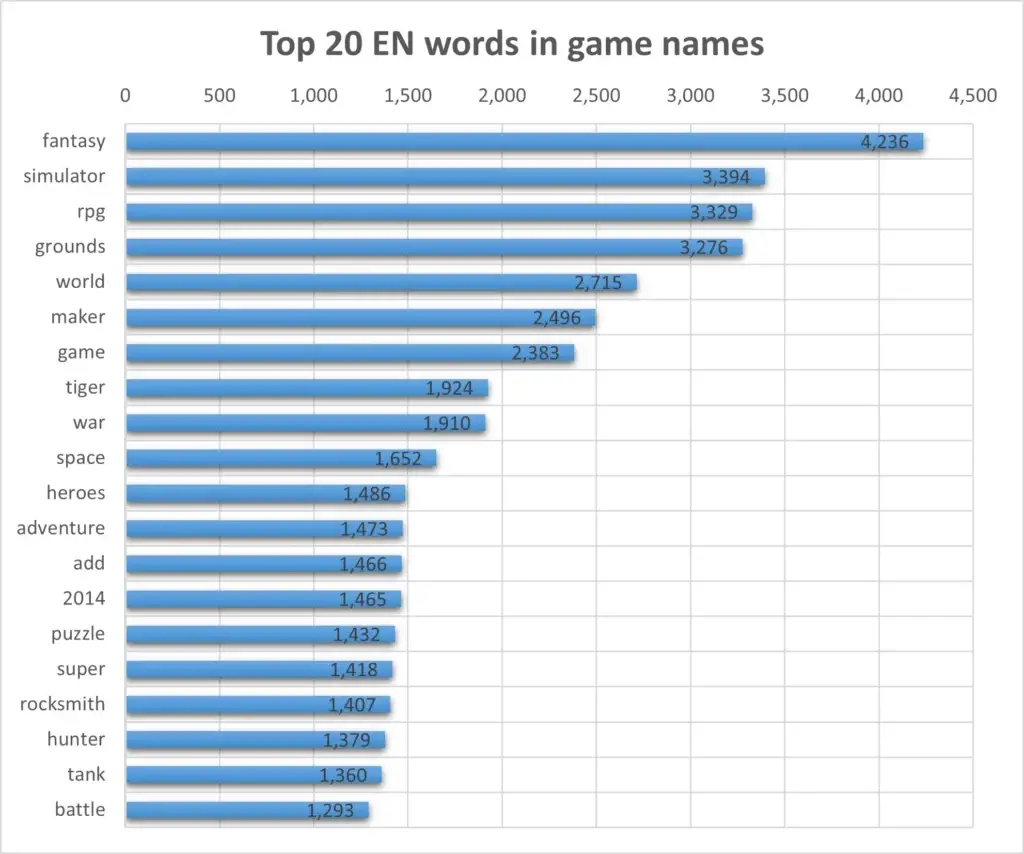
So, what are the top 20 words favored by developers in English names? “Fantasy”, of course, is the perfect epitome of the purpose of video games, followed by a self-explanatory genre term “simulator” that allows us to experience another life. Most words are familiar, yet the word “add” confused me. Then I prowled the data set again and saw a couple of names like “GunsoulGirl 2-Add Patch”, “OMSI 2 Add-on Digibus Mirage”, 14 add-ons for X-Plane 12, and more than 100 add-ons for the Train Sim World franchise. Well, it turns out that launching (un)reasonably many add-ons is a proven business strategy in the video game industry.
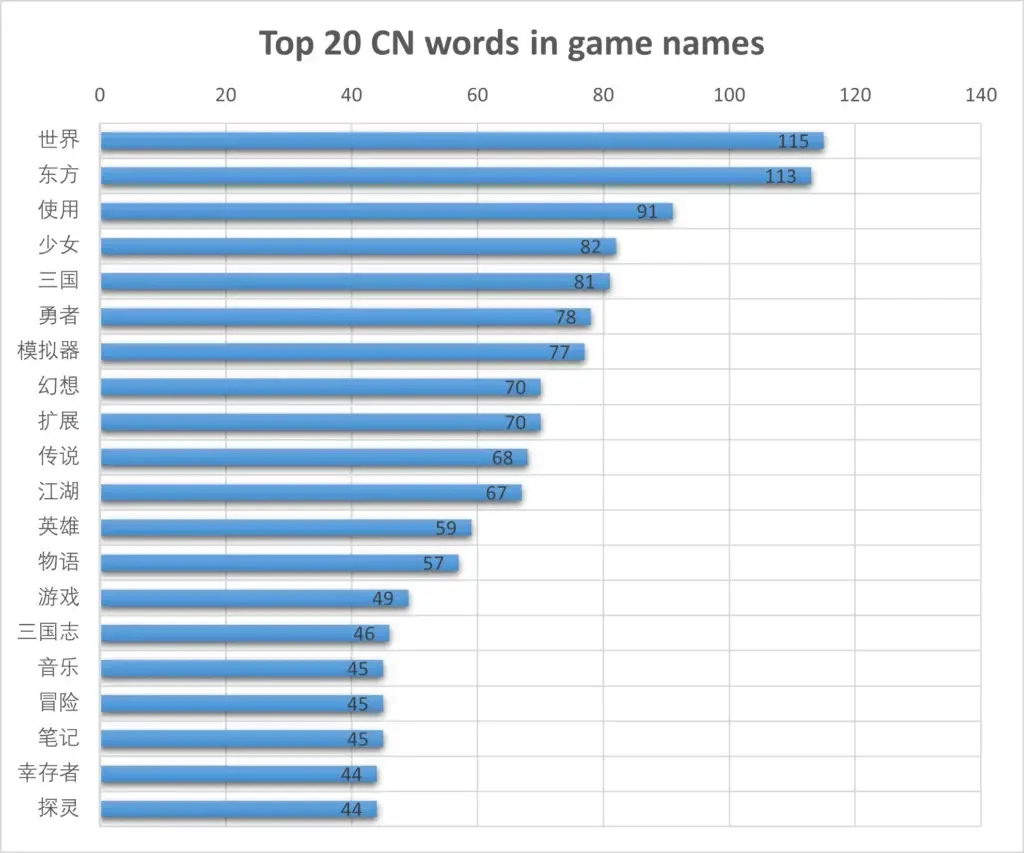
In Simplified Chinese, what can the top 20 trendy words tell us about Chinese gamers and their taste? “世界/world” is one of the other identical words overused in English, along with “幻想/fantasy”, “英雄/heroes”, “游戏/game”, and “模拟器/simulator”. Here we can see that English gamers prefer a couple of blood-mongering words like “war”, “hunter”, “tank”, and “battle” while Simplified Chinese gamers are attracted by “东方/touhou”, “少女/maiden”, “三国(志)/3-kingdom”, “幸存者/survivor”, and “探灵/ghost hunting”, displaying diffused preferences across the community.
Summary
A catchy name can be designed with multiple approaches. Working on word choices, trendy or not, is one of many practical solutions in localization. I hope this little fun analysis may help you to create an outstanding name, no matter whether you are a developer, publisher, or a video game localizer like me.

About the Author
George Ou is a localizer. He serves gamers with his words in print and digital. His deliveries have been read in over 200 popular culture publications.
